O data lake sempre foi considerado um dos pilares fundamentais na base das organizações orientadas a dados, uma filosofia de negócios pela qual todas as empresas modernas se empenharam na última década. Em essência, um data lake é uma grande base de informações no qual os dados corporativos podem ser transferidos, no estado em que se encontram, sem transformações, para tornar os dados acessíveis para todas as funções; em outras palavras, uma democratização do acesso aos dados.
Nesse tipo de projeto, os dados recebem um valor intrínseco, quase natural. Através de novas tecnologias, que vão da engenharia à ciência de dados, qualquer pessoa pode acessá-los e extrair insights, sem a necessidade de ter muita experiência sobre o contexto do qual os dados derivam.
Trabalhando ao longo dos anos em muitos projetos relacionados, no entanto, descobrimos que o modelo sofre de algumas complicações subjacentes. Este impulso de extrair os dados brutos do domínio de origem e processá-los em plataformas centralizadas gerou dois problemas que são familiares para quem possui experiência neste campo: A dificuldade inerente em pesquisar e interpretar os dados para aqueles que ignoram sua origem e a baixa qualidade crônica dos dados decorrente do fato de que quem extrai os dados de seu domínio de origem geralmente não é responsável por sua utilização.
Para resolver esses problemas, as empresas estão se organizando cada vez mais com estruturas de governança de dados complexas, que definem responsabilidades, processos e funções para garantir a clareza dos dados e preservar sua qualidade. No entanto, a solução para esses problemas não pode ser apenas organizacional. As empresas também precisam de ajuda técnica para simplificar a estrutura do modelo.
Sobre esse assunto, a visão da autora, Zhamak Dehghani, em seu artigo “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”[1] é muito interessante. Nele, ela propõe uma nova forma de gerenciar os dados da empresa ao questionar a análise dos dados na própria origem, domínio no qual os dados nascem. De acordo com esta abordagem, são os próprios especialistas do domínio de origem, os responsáveis pela referida interpretação e qualidade dos dados. Por exemplo, a responsabilidade pelos dados do cliente estariam sob a área de CRM, a responsabilidade pelos dados do orçamento sob a área de gestão, pelos dados de vendas online sob a área do e-commerce, entre outros. É fácil entender como neste novo contexto os problemas relacionados à interpretação e à qualidade dos dados diminuiriam substancialmente, dada a experiência abundante no domínio da origem dos dados.
O principal aspecto da intuição a respeito do data mesh, entretanto, está na solução proposta para evitar uma recaída no velho mundo dos silos de informação, no qual os dados eram mascarados e perdidos nas diversas áreas de origem. Nos domínios do data mesh, são atribuídas as responsabilidades de criar produtos de dados que são ferramentas de software para visualização e interpretação de dados a serem publicados em toda a empresa. Estes produtos são disponibilizados internamente na empresa e podem ser remunerados, ou seja, podem ter um orçamento para seu crescimento, dependendo do quanto são efetivamente utilizados ou subscritos por outros utilizadores.
Cria-se um mercado livre – e este é o desafio das ferramentas de suporte ao data mesh – no qual todos os usuários possam encontrar e consumir todos os produtos de dados corporativos, também se cria um impulso benéfico para divulgação e compartilhamento de dados dada pela competição natural pelo orçamento entre os domínios.
Os dados reportados desse modo são da responsabilidade da área origem, porém em um mercado no qual os responsáveis pela informação são motivados a expor esses dados e torná-los compreensíveis e de qualidade. Isso coloca essa experiência de domínio da informação como base da valorização dos dados.
Como o data mesh é composto
O data mesh baseia seus fundamentos teóricos no modelo arquitetônico de Projeto Dirigido por Domínio (DDD – Domain-Driven Design), segundo o qual o desenvolvimento do software deve estar intimamente ligado aos domínios de negócios de uma organização. No DDD, cada área organizacional pode ser representada por um modelo de domínio, que é uma combinação de dados, comportamentos característicos e de lógica de negócio que orientam o desenvolvimento do software de domínio. O principal objetivo do DDD é criar um software pragmático, consistente e escalável, dividindo a arquitetura em serviços dentro de domínios individuais e focando em sua reutilização na composição dos diferentes produtos de software de suporte para a empresa. A primeira implementação de DDD em software corporativo foi a revisão de aplicações monolíticas para arquiteturas baseadas em micro-serviços: Cada micro-serviço é circunscrito em um domínio e é responsável por satisfazer os requisitos de uma funcionalidade específica, fornecendo uma função de aplicação para todos os produtos que o solicitam.
O data mesh aplica o DDD às arquiteturas no domínio de dados. Os produtos de dados, como são chamados, permitem acesso aos dados do domínio por meio de funções elementares que expõem interfaces precisas e disponibilizam dados brutos, pré-processados ou processados. Assim como micro-serviços são componentes de software que expõem funcionalidades elementares da aplicação, os produtos de dados são componentes de software que expõem dados elementares e funcionalidades analíticas dentro do domínio. Os produtos de dados têm o objetivo de dividir as funções analíticas do domínio em produtos elementares e reutilizáveis, tal como os micro-serviços subdividem as funções da aplicação.

Tal como acontece com os micro-serviços, também no data mesh o novo modelo desagregado precisa de uma série de regras e de ferramentas para manter uma boa governança do todo.
Em primeiro lugar, os produtos de dados devem respeitar algumas características, que são funcionais para criar o livre mercado citado anteriormente. Independentemente de como a interface específica de acesso a dados é criada – é possível dar acesso por meio de uma API, por meio de uma exibição em um banco de dados ou de um sistema de virtualização – ou como o tipo de dados que é disponibilizado, os produtos de dados devem respeitar regras identificadas na sigla DATSIS, de acordo com a qual um produto de dados deve ser:
- Detectável (Discoverable): Os consumidores devem ser atribuídos para pesquisar e identificar os produtos de dados criados pelos diferentes domínios
- Endereçável (Addressable): Os produtos de dados devem ser identificados com um nome exclusivo após uma nomenclatura comum
- Fidedigno (Trustworthy) – os produtos de dados são construídos pelos domínios que mantêm os dados e devem disponibilizar dados de qualidade
- Auto-Descritivo (Self-Describing): Os consumidores precisam ser capazes de utilizar dados sem ter de solicitar aos especialistas do domínio sobre seu significado
- Integrado (Integrated): O produto de dados deve ser criado seguindo padrões compartilhados para serem facilmente reutilizados, a fim de criar outros produtos de dados
- Seguro (Secure) – O produto de dados deve ser seguro por projeto e o acesso aos dados deve ser regulado centralmente através de políticas de acesso e de padrões de segurança
Somente respeitando essas regras, é possível criar produtos de dados que permitam um projeto de malha eficaz e confiável.
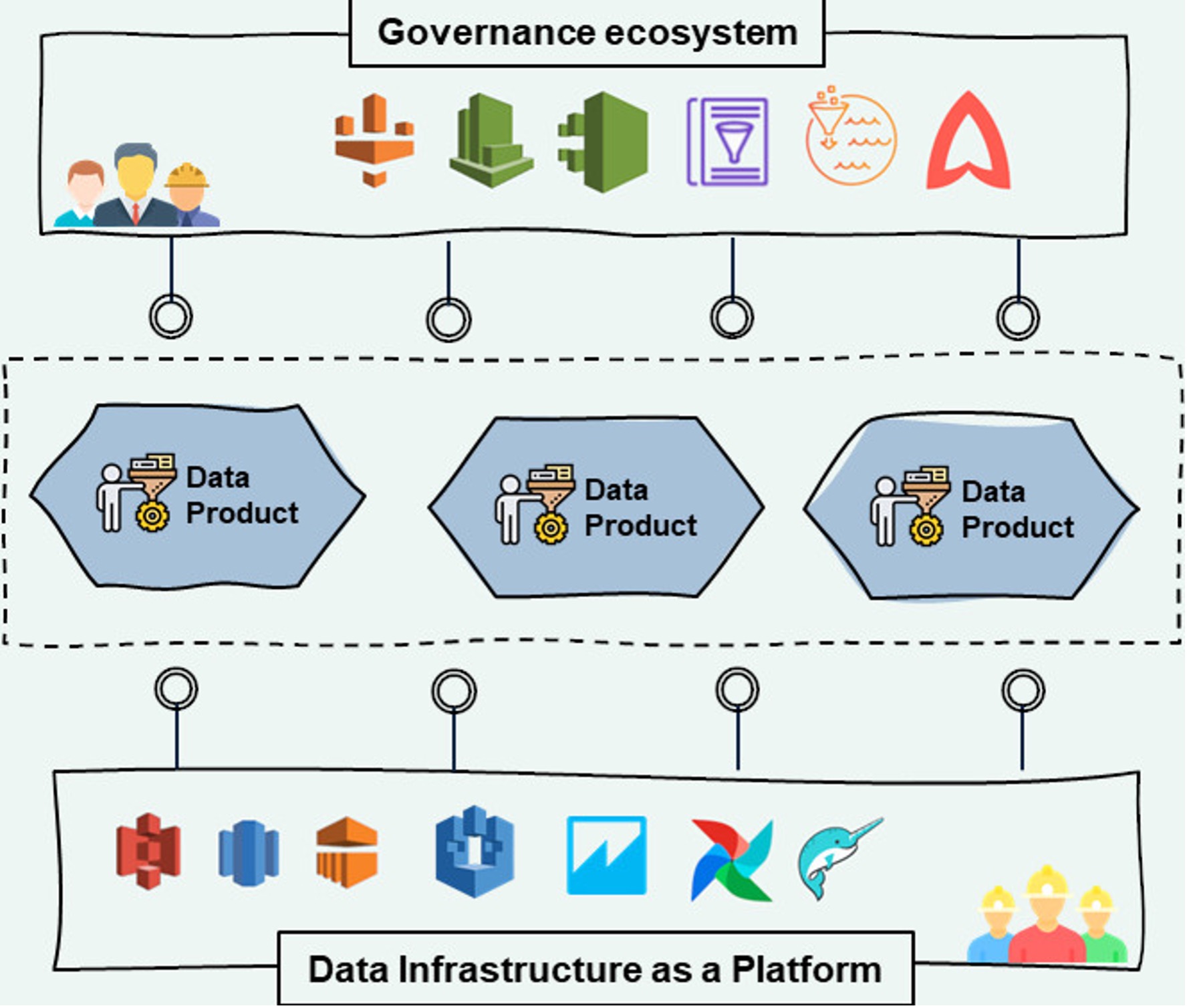
Movimentando-se para as ferramentas, existem dois fatores essenciais para construir um data mesh em funcionamento: Infraestrutura de dados como uma plataforma e uma governança de ecossistema.
Ao impor a exigência de que os domínios de aplicações individuais desenvolvam seus produtos de dados, a organização corre o risco de aumentar a taxa de heterogeneidade das tecnologias em uso, tornando, portanto, a estratégia de terceirização muito complexa. Na implementação de um data mesh, contudo, é importante que uma organização se equipe com uma plataforma de infraestrutura comum – data infrastructure as a platform – que fornece os blocos de desenvolvimento básico para a criação e a utilização de produtos de dados para todos os domínios, como por exemplo: -Armazenamento, pipeline, banco de dados e funções de cálculo. Qualquer domínio que deseja configurar seus próprios produtos de dados terá de fazer uso dessas etapas, acessando a infraestrutura de dados como uma plataforma no modo de autoatendimento. Isso permite a padronização do desenvolvimento de produtos de dados e a introdução de uma linguagem comum entre os vários domínios. Plataformas em Nuvem PaaS são uma opção interessante para construir esta infraestrutura comum sobre a qual baseia-se os produtos de dados; uma opção que poderia oferecer uma adoção balanceada entre custos e velocidade de implementação.
A criação de produtos de dados de forma distribuída também apresenta riscos, como o aumento da taxa de duplicidade e da complexidade do acesso aos dados, perdendo os objetivos de qualidade e de responsabilidade referentes ao paradigma do data mesh. Para isso, é muito importante que a organização esteja equipada com ferramentas de governança para o ecossistema, que ajudam a fornecer visibilidade e compreensão para produtos de dados, ferramentas em que cada produto de dados pode ser registrado e tornado consequentemente pesquisável e reutilizável, de acordo com as políticas específicas de autenticação e de autorização.
Perspectiva técnica
Agora que os conceitos de produto de dados, a infraestrutura de dados como uma plataforma e a governança do ecossistema foram apresentados, vamos entrar em uma perspectiva mais técnica para deixar mais clara essa introdução.
Antes de tudo, os produtos de dados são nada mais do que conjuntos de componentes tecnológicos, muitas vezes já conhecidos por empresas para carregamento, armazenamento, processamento e análise de dados. Por exemplo, tomemos um produto de dados que é uma ferramenta para produzir um relatório baseado em dados de um domínio e examinar os componentes que fazem parte dele.
Conforme mencionado, os componentes de construção do produto de dados vêm da infraestrutura de dados como uma plataforma. Aqui encontramos tecnologias estabelecidas, incluindo armazenamento de arquivos (file system storage) e arquitetura para dados de eventos, uma camada de processamento em lote, de streaming e ferramentas de consumo de dados para relatórios, BI, ML e AI. Eles são ferramentas já amplamente conhecidas e adotadas.
Nesse exemplo do produto de dados que produz um relatório, os blocos de construção podem ser um armazenamento que mantém os arquivos dos quais extrair dados, um mecanismo Spark para extração e processamento, um banco de dados para suporte aos dados processados, uma interface para a análise e uma visão para o relatório, e uma API para entrega dos resultados.
Para a realização do produto de dados, a infraestrutura de dados como uma plataforma também possui a tarefa de fornecer as ferramentas para permitir a orquestração de componentes e a colaboração entre os usuários. Nele encontramos tecnologias de orquestração (como Airflow, Dagster e DataFactory), que permitem coordenar a execução de processamento e as ferramentas mais recentes de modelagem de dados, a fim de facilitar a colaboração na fase de desenvolvimento entre engenheiros e analistas (p. ex., Dremio e o Data Build Tool).
No caso de nosso produto de dados, essas ferramentas permitem a execução ordenada dos comandos e das funções que geram o relatório e uma colaboração mais eficaz entre o Engenheiro de Dados que utiliza o Spark para gerenciar os dados no armazenamento, o modelador que estruturou o modelo de dados no banco de dados, o analista que o utiliza para a exploração e o desenvolvedor que distribui os resultados na forma de uma API.
Neste ponto, o produto de dados está pronto para ser consumido mesmo fora do domínio, e aqui as ferramentas de governança ecossistêmica adequadas para gerenciar o catálogo e a distribuição de produtos de dados entram em jogo. Entre as principais ferramentas para organização entre domínios, encontramos tecnologias federadas, tecnologias de catalogação de produtos de dados e tecnologias de descoberta de dados (como Amundsen, Metacat, Atlas), o que os torna visíveis e utilizáveis para os usuários finais. Através da inclusão dessas ferramentas, os usuários de outros domínios podem pesquisar e acessar o produto de dados, utilizando os recursos de pesquisa semântica ou a navegação através do catálogo de produtos de dados central da empresa.
Para completar a plataforma de governança do ecossistema, há funções que supervisionam a conformidade, a qualidade de dados, o controle de acesso e o monitoramento. O novo Data Steward, na hipótese de um ecossistema com base na AWS, explorará os alertas automáticos da AWS Comprehend para identificar violações de privacidade, o Glue DataBrew para controlar a qualidade dos resultados do novo produto de dados, o Lake Formation para controlar as permissões internas e externas para o domínio e o CloudTrail para monitorar o acesso e a utilização.
Perspectiva Organizacional
Um aspecto final, mas importante, a ser considerado na avaliação do paradigma do data mesh é a adaptação organizacional que sua introdução pode exigir. Nessa perspectiva, a transição é mais fácil para aqueles que já adotaram modelos organizacionais ágeis com chapters de domínio de competência e squads de projeto.
O princípio do fornecimento de dados como “produto” vê o nascimento de novos papéis, como os Data Product Owners – semelhantes aos Product Owners já conhecidos – dentro dos domínios individuais; figuras responsáveis pelo ciclo de vida de produtos de dados (planejamento, monitoramento etc.) e para a execução da estratégia de dados de domínio.
Os perfis profissionais já presentes nas organizações atuais serão distribuídos nos domínios das empresas: A descentralização da propriedade sobre os dados e de seu processamento por meio do domínio da competência significa que figuras como Engenheiros de Dados e Arquitetos de Dados serão distribuídas dentro dos domínios individuais. Os engenheiros de dados do domínio “cliente” devem ser identificados, como por exemplo, no passado em que os desenvolvedores de micro-serviços verticais surgiam dentro do mesmo domínio.
Em tal organização distribuída sobre os domínios, no entanto, a função responsável pelas políticas de governança (interoperabilidade, segurança, conformidade etc.) permanece centralizada. Ela é uma entidade organizacional central que garante a aplicação de políticas ao nível de cada domínio. Essa entidade é composta por figuras técnicas no nível empresarial (por exemplo, Arquitetos de Dados Corporativos, Arquitetos de TI Empresarial etc.), representantes dos domínios e especialistas em segurança e conformidade.
A única outra função que permanece centralizada no modelo é a de supervisionar a infraestrutura de dados como uma plataforma que gerencia a infraestrutura para todos os domínios com habilidades de engenharia e de operação.

O datamesh é, portanto, uma composição de muitos aspectos, em uma possível transformação do mundo de dados em direção a um modelo mais ágil e unido.
O Bip Xtech, nosso Centro de Excelência em tecnologias exponenciais, equipe com especialistas em todas as disciplinas mais avançadas em torno da estratégia e gestão de dados, desde a governança de dados até arquiteturas de micro-serviços; somos capazes de fornecer todos os aprendizados necessários para uma transição de sucesso ao data mesh
Caso você esteja interessado em uma apresentação de nossa oferta ou apenas em uma reunião com um de nossos especialistas, preencha esse formulário e entraremos rapidamente em contato.








