



Sendo adotada como a nova tendência de gerenciamento de dados, o Data Lakehouse vem apresentando um grande crescimento em muitas empresas do campo. Essa nova arquitetura, permite que estruturas e esquemas como os usados em um Data Warehouse sejam aplicados aos dados não estruturados do tipo que normalmente seria armazenado em um Data Lake.
Os usuários de dados conseguem acessar as informações mais rapidamente e começar a colocá-las em prática, podendo ser Analistas de Dados ou Cientistas de Dados ou, até mesmo usuários em várias outras funções que estão cada vez mais utilizando os benefícios de se aprimorar com recursos de análise.
O Lakehouse é a tentativa de unir as vantagens do Data Lake e Data Warehouse, tendo uma abordagem opinativa para construir Data Lakes, adicionando atributos de Data Warehouse, isto é, combinando a flexibilidade, economia e simplicidade do Data Lake com o gerenciamento de dados e Transações ACID de Data Warehouse, permitindo BI e Machine Learning. O objetivo principal desta nova tecnologia é resolver estes desafios enfrentados no Data Warehouse e Data Lake reduzindo os custos operacionais, simplificar o processo de transformação e melhorar a governança.
O Lakehouse se tornou uma forma de centralizar e unificar as fontes de dados e esforços de engenharia em uma organização. Essencialmente, o uso do Lakehouse permite que todos os usuários possam explorar os dados, independentemente de suas capacidades técnicas. Tornando-se um sistema de armazenamento de dados de baixo custo no Data Lake, utilizando um formato aberto de arquivos (por exemplo, o parquet). Assim como no Data Lake, o Lakehouse separa os recursos de processamento e armazenamento, ou seja, é possível que vários motores de processamento processem os mesmos dados sem ter que armazenar os dados de forma duplicada no Data Lake e no Data Warehouse.
Estes formatos abertos de arquivos amenizam o problema de trabalhar com dados estruturados no Data Lake. Mas, continua uma questão em aberto: como fornecer funcionalidades básicas dos Data Warehouses, como transações ACID, gerenciamento, versionamento, auditoria, indexação, cache e otimização de consultas utilizando estes formatos de arquivos? Se estes desafios não forem resolvidos, o Lakehouse seria semelhante a um Data Lake.
Uma solução viável para esses problemas seria utilizando uma camada de metadados transacional, implementada sobre o sistema de armazenamento para definir quais objetos fazem parte de uma versão da tabela. Além disso, as soluções de Lakehouse implementam outras otimizações para melhorar ainda mais o desempenho das consultas, como cache, estruturas de dados auxiliares (índices e estatísticas) e otimizações no layout do dado.
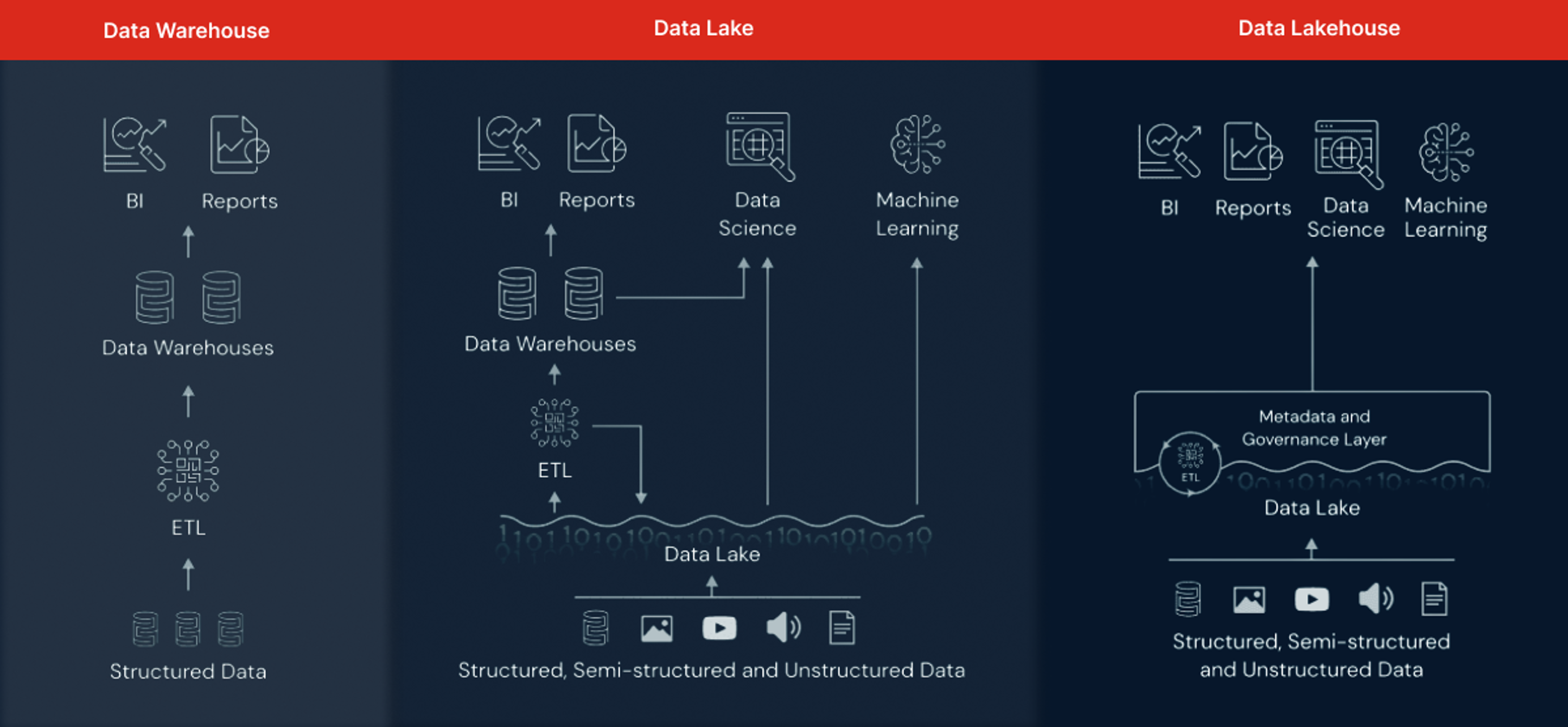
Figura 1 – Comparação das Arquiteturas do Data Warehouse, Data Lake e Lakehouse
Como os Lakehouses também separam o processamento de armazenamento, diferentes aplicações podem rodar sob demanda em um cluster separado (exemplo, cluster de GPU para Machine Learning), enquanto podem acessar diretamente os mesmos dados armazenados. Assim, é possível compartilhar recursos computacionais entre aplicações com overhead reduzido. Esta separação também permite definir orçamentos específicos em vários níveis e estágios. Por exemplo, você pode subir um cluster Hadoop na nuvem sob demanda, rodar jobs Spark sobre os dados do Data Lake e depois derrubar o cluster, pagando apenas pelo que usou de processamento. Assim não é preciso manter o cluster rodando 24×7, já que eles estão armazenados em um barramento de dados compartilhado no Data Lake.
O Lakehouse possui componentes de ingestão, gerenciamento e análise dos dados que permite que diferentes ferramentas possam explorar estes dados para atender as necessidades dos usuários. As arquiteturas Lakehouses se tornaram úteis tanto para aplicações de análise de dados e Business Intelligence, quanto para Data Science e Machine Learning.
Estabelecendo valores para a construção de Lakehouses confiáveis
Os Lakehouses permitem eficiência na ingestão de dados (batch/streaming), na construção de pipelines de dados escalonáveis e na execução destes em produção, além de automatizar todo este fluxo, garantindo confiabilidade e escala.
Com o Data Lakehouse, se beneficia por uma abordagem unificada e arquitetura simplificada que garante confiabilidade em todo seu processamento, seja em batch e/ou streaming. Experimentando pipelines de dados robustos que garantem confiabilidade de dados com atomicidade, consistência, isolamento e durabilidade, e garantias de qualidade de dados em todo o processo.
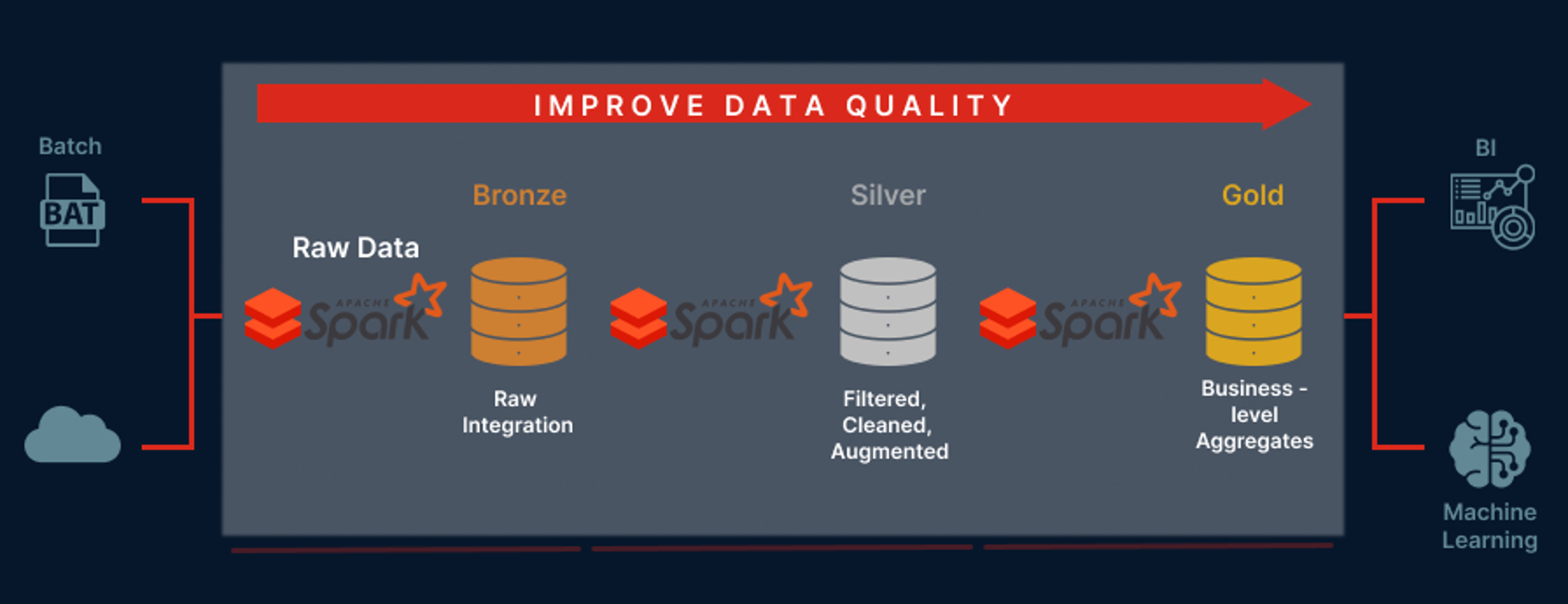
Figura 2 – Pipeline de Dados
A figura acima é um demonstrativo de um pipeline de dados simplificado e eficiente. Conforme a configuração apresentada, há a experiência de uma redução de tempo computacional e custos com uma execução de nuvem escalável. O processo é alimentado através de clusters Spark altamente otimizados e recursos de nuvem elástica que podem ser escalonados automaticamente para cima e para baixo, dependendo da carga de trabalho (otimizando o custo).
Características principais de um Lakehouse
Em um Lakehouse corporativo, quando falamos de suporte a transações, muitos pipelines de dados leem e gravam dados simultaneamente, utilizando SQL (na maioria dos casos). O sistema deve ser capaz de racionalizar sobre a integridade dos dados e deve possuir mecanismos robustos de governança e auditoria.
Permitem o uso de ferramentas de BI diretamente nos dados de origem. Reduzindo a desatualização e a latência, e diminuindo o custo de ter que operacionalizar duas cópias dos dados em um Data Lake e um Warehouse.
O armazenamento é desacoplado da computação, significando que o armazenamento e a computação usam clusters separados, podendo ser escalonados para muito mais usuários simultâneos e tamanhos de dados maiores. Alguns Data Warehouses mais atuais também possui essa propriedade.
Os formatos de armazenamento que usam são abertos e padronizados (como Parquet), fornecendo uma API para que uma variedade de ferramentas e mecanismos, incluindo Machine Learning e bibliotecas Python / R, possam acessar os dados diretamente de maneira eficiente.
O Lakehouse pode ser usado para armazenar, refinar, analisar e acessar tipos de dados necessários para muitos novos aplicativos de dados, incluindo imagens, vídeo, áudio, dados semiestruturados e texto.
Possui suporte para diversas cargas de trabalho, incluindo Data Science, Machine Learning e SQL. Várias ferramentas podem ser necessárias para oferecer suporte a todas essas cargas de trabalho, mas todas elas dependem do mesmo repositório de dados.
Os relatórios em tempo real são padrões em muitas empresas. O suporte para streaming elimina a necessidade de sistemas separados com a finalidade de atender aplicativos de dados em tempo real.
Desafios que podem ser superados com uma abordagem Lakehouse
Um dos maiores benefícios de um Lakehouse é que ele unifica todas suas equipes de dados (engenheiros de dados, cientistas de dados e analistas – em uma única arquitetura).
Outra vantagem é a facilidade na quebra de silos de dados, fornecendo uma cópia completa e consistente de todos seus dados em um local centralizado. Isso permite que todos em sua organização possam acessar e gerenciar tanto dados estruturados como não estruturados.
A abordagem Lakehouse, de forma contínua, pode processar lote (batch) e streaming de dados, atualização de tabelas e painéis quase em tempo real para que seus dados estejam sempre gerando valor, permanecendo atualizado e nunca se tornando obsoleto. Usando formatos e padrões abertos que permitem que seus dados sejam armazenados independentemente das ferramentas usadas atualmente para o processamento, tornando mais fácil a qualquer momento migrar seus dados para um outro fornecedor ou tecnologia.
Quem deve usar a arquitetura Lakehouse?
Organizações que desejam dar o próximo passo em sua jornada de análise, passando de BI para Inteligência Artificial. Atualmente, as empresas estão procurando dados não estruturados para informar suas operações e tomadas de decisão orientadas por dados simplesmente devido à riqueza dos insights que podem ser extraídos deles.
Os Data Lakehouses são baratos de escalar (diferentemente dos Data Warehouses) porque a integração de novas fontes de dados é automatizada – eles não precisam ser ajustados manualmente os formatos e esquemas de dados da organização. Eles também são “abertos”, o que significa que os dados podem ser consultados de qualquer lugar usando qualquer ferramenta, em vez de limitados a serem acessados por meio de aplicativos que só podem manipular dados estruturados (como SQL).
A abordagem do Data Lakehouse provavelmente se tornará cada vez mais popular à medida que mais organizações começarem a entender o valor de usar dados não estruturados junto com Inteligência Artificial e Machine Learning.
Na jornada de análise, é um avanço na maturidade do modelo combinado de Data Lake e Data Warehouse que até recentemente era visto como a única opção para organizações que desejam continuar com fluxos de trabalho de análise e BI legados, ao mesmo tempo em que migram para iniciativas de dados inteligentes e automatizadas.
Case
Para ilustrar uma solução através da estruturação de um Data Lakehouse podemos usar o cenário do Grupo Boticário, que tinha como principal desafio, centralizar e estruturar os dados de clientes e fornecedores, das mais diversas origens, em um único local. A centralização destes dados garantia análises e tomadas de decisão mais assertivas e menos complexas para O Boticário.
De acordo com Henrique Rubem Adamczyk, CIO do Grupo Boticário, a empresa analisou várias soluções disponíveis no mercado e optou pelo que considera mais aderente às suas necessidades. A solução proposta foi a estruturação de um Data Lakehouse. Para esse projeto foi necessário um controle de governança sobre o acesso aos dados, considerando todas as diretrizes da Lei Geral de Proteção de Dados (LGPD) em relação às informações sensíveis da empresa e de seus clientes.
Os dados passaram por um processo de limpeza e qualificação a partir de cargas de trabalho batch (agendados) e stream (em tempo real). Isso permite ter visualizações consistentes, otimizadas e fáceis de utilizar.
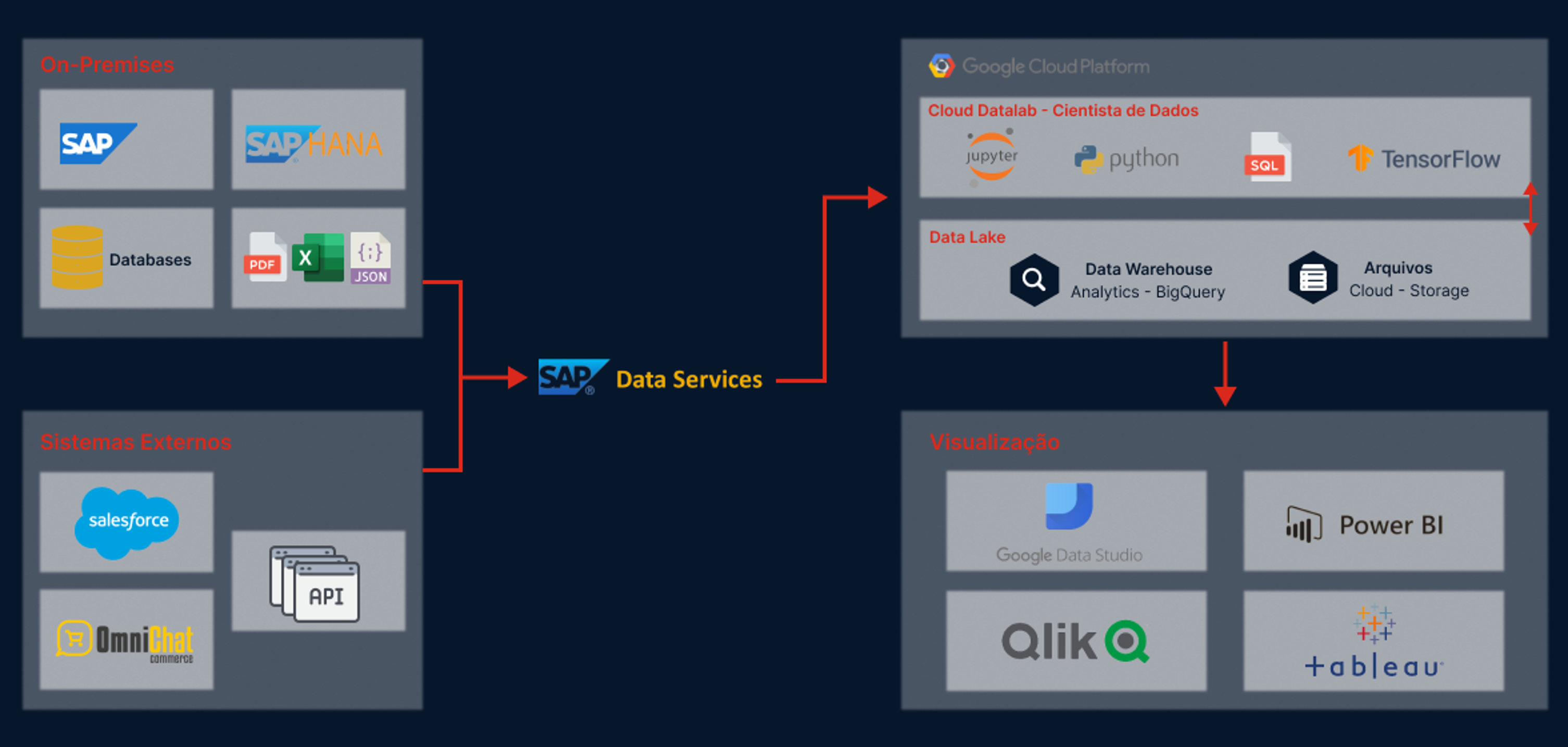
Figura 3 – Arquitetura do Projeto
Com o Data Lakehouse, o Grupo Boticário percebeu uma melhoria significativa no acesso aos seus dados, reduzindo o tempo para analisar um determinado resultado e conseguir tomar uma decisão com base nos relatórios observados.
Além disso, com o acesso descomplicado ao repositório de dados, houve uma melhoria significativa na compreensão geral das informações, uma vez que todos os envolvidos em uma análise puderam visualizar as mesmas informações e construir novos planos com mais inteligência e assertividade.
Os Data Warehouses e os Data Lakes vão deixar de existir?
Ao contrário do que muitos pensam os Data Warehouses e os Data Lakes não deixarão de existir. O que veremos é a integração desses repositórios de dados ao mesmo tempo que testemunhamos a evolução natural da tecnologia. Data Lakehouse é uma tecnologia de armazenamento muito promissora, mas seu valor será extraído somente se a empresa já tiver uma forte cultura data-driven. O Data Lakehouse será a evolução natural no amadurecimento da infraestrutura de dados de uma empresa.
Em um mundo cada dia mais conectado e rodeado de dados, com diferentes tipos e formatos, aumenta a necessidade da centralização das informações para que possamos chegar a análises, resultados e descobertas (insights) confiáveis e de qualidade. Aos poucos, os Lakehouses fecharão essas lacunas, mantendo as propriedades principais de serem mais simples, mais econômicos e mais capazes de atender a diversas aplicações de dados.
Serviços BIP xTech
A xTech é um centro de excelência do Grupo Bip, com longa trajetória na definição de estratégias, análise de serviços, desenho e governança de soluções de tecnologia.
A BIP xTech guia seus clientes a atingirem essa alta performance e mantê-la, inclusive com a migração para sistemas em nuvem, o que traz os benefícios do que há de melhores práticas e otimizações de custo e disponibiliza sistemicamente informações valiosas para excelência operacional com conformidade, segurança, disponibilidade, flexibilidade de crescimento e possibilidades de melhoria contínua.
Estamos, como sempre, ao lado dos nossos clientes para os ajudar a aproveitar as oportunidades oferecidas com a migração para sistemas em nuvem, também em virtude das nossas fortes competências em Estratégia, Arquitetura e Governança de dados, que cada vez mais se irão se convergir para revolucionar a eficiência de dados das empresas.








